Intelligence
Dynamic Path Prediction
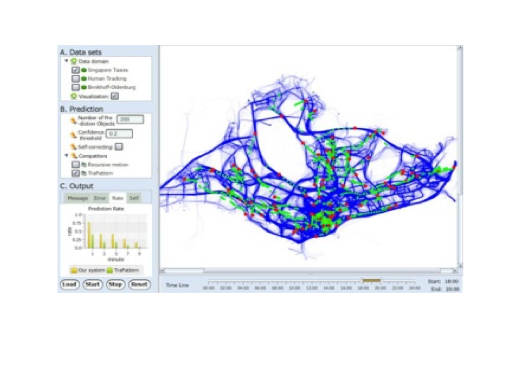
A Semi-Lazy Learning System to Probabilistic Path Prediction in Dynamic Environments
Path prediction has a board range of application, including navigation, traffic management, personal positioning, actionable advertising. However, in dynamic environments (such as urban space), since the movement of objects is affected by many factors, path prediction is a difficult and challenging, which is of interest to SeSaMe and its researchers.
LEADER is a prototype to support probabilistic path prediction in dynamic environments. The core of our system is a “semi-lazy” approach to probabilistic path prediction, which builds prediction model on the fly using historical trajectories that are selected dynamically based on the trajectories of target objects.
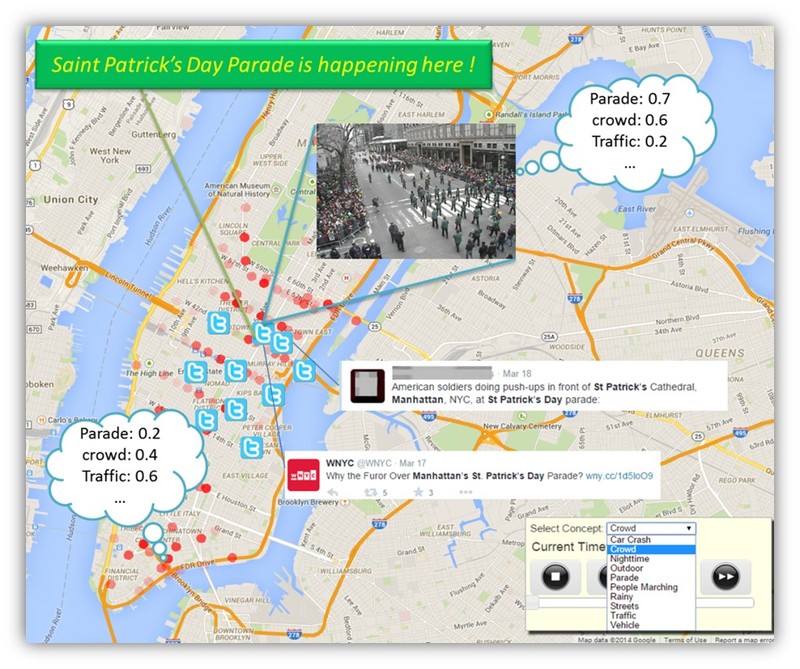
CamTweet
From analogous cameras to digital ones, we have seen a great advance of this physical sensor, observed the prevalence of CCTV cameras monitoring our world. However, high bandwidth consumption and privacy concerns prevent them being widely used by the public. In Industry 4.0 era where all things/humans are closely connected in cyber-physical world, we design a new paradigm of smart tweeting cameras in which socially connected cameras can be configurable for different applications, and “tweet” (like humans) events of interest.
F-formation Social Interaction
In the literature, social interaction analysis is regarded as one type of complex human activity analysis problem. Under general scenario, specific definitions must be provided in advance to detect the given social interaction type. Considering the unconstrained nature of social interactions, it is not feasible to enumerate all the possible types of ad-hoc social interactions. In this work, we propose an extended F-formation system for robust interaction and interactant detection. Differing from the existing works on human activity analysis, it utilizes the F-formation model from sociology literature that considers the spatial aspect of social interactions, which is easier to detect in the generic social interaction settings. In addition, we also modelled the temporal aspect of interaction. Our novel extended F-formation system employs a heat map based feature representation for each unique individual, namely Interaction Space (IS), to model their respective location, orientation, and temporal information. In our work, the individual's spatial location and orientation are detected with multiple Kinect depth sensors. Given the interaction space of all individuals at a given frame, we detect the interaction centers (i.e., o-space) and the respective interactants, as well as the location of the best view camera. The proposed temporal-encoded interaction space based approach is evaluated on both the synthetic data and real-world environment.

Visual Saliency
Saliency in Context (SALICON) is an ongoing effort that aims at understanding and predicting visual attention. We created a new psychophysical paradigm to collect large-scale human attentional data during natural explorations on images. With this paradigm, we built the SALICON dataset with 20,000 natural images, by crowdsourcing the data collection with Amazon Mechanic Turk (AMT). The SALICON dataset is by far the largest in both scale and context variability.

Crowd Level Estimation
A crowd level estimation technique has been developed to determine the level of crowdedness in a particular location. It is based on a foreground occupancy algorithm. It has been applied to a mobile app called NUS Foodie, which provides information about food outlets in NUS, enables the user to rate the outlets, allows the food stall owners to carry out promotions and most interestingly informs the user about the level of crowdedness in specific food outlets on campus.
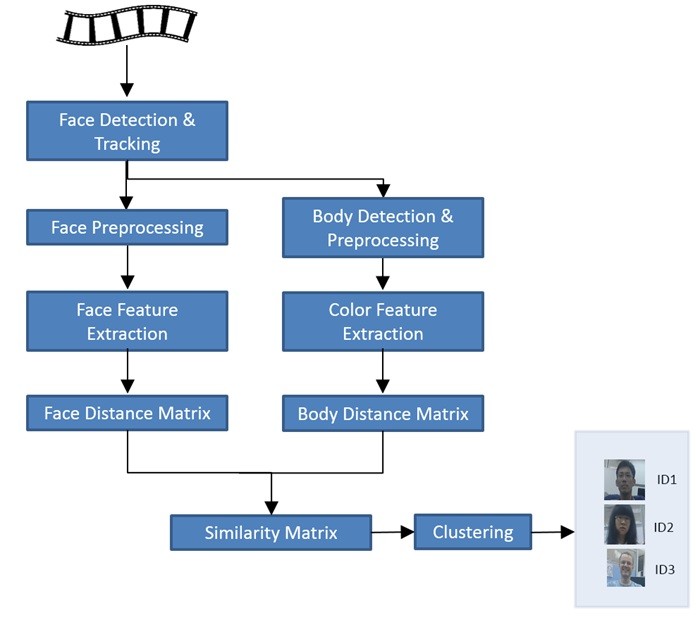
Automatic Person Analytics with Egocentric Vision
In this work, we built a prototype to analyze a video footage and generate a unique set of persons who appear in the video. Here, we first perform face detection and tracking in the entire video footage, where each candidate tracking output (denoted as face-track) consists of the faces of the same individual. Each face-track is geometrically normalized to an intermediate format with detected facial feature points, followed by a generic face-based quality assessment is employed to reject or select a subset of facial images for identification purposes. The size normalized and quality checked face-tracks are then represented with Locally Sparse Encoded Descriptor (LSED), where one face descriptor is generated for each face-track. Finally, graph-based clustering technique is applied over the face-tracks' descriptor to generate the unique person set. The upper body color attribute of each person is also utilized to enhance the quality of the unique person set. The sensors data, such as localization, is used to geo-tag each detected face track. The non-visual sensor data allows our application to improve the accuracy of vision algorithm, as well as to geo-tag the detected individual. Given a list of persons in the personal contact list, the system can automatically name the known individuals in the video, or generate suggestion for each detected individual. Unseen individual will be automatically listed (in map-view or list-view) for user to annotate.

Automatic Self-Quantification of Presentation with Egocentric Vision
In this work, we showcase a multi-sensor based self-quantification framework for individual presentation analysis using First-Person-View (FPV) devices. Given a video captured with FPV devices, such as Google Glass, we analyse the presenter's performance on four categories, i,e., vocal behaviour, body language, engagement with audience, and presentation state. For this work, we analyse the raw data from audio sensor, visual sensor, and motions sensors. In addition, we extend the framework to incorperate data from ambient sensors (such as RGB-D sensors or CCTV camera) and audiences' FPV devices. A visualized analytic feedback is automatically generated. Experiment results with a newly collected dataset and user study shows promising results for this work. Overall, this application aims to provide effective analysis of individual behaviour, where the initial prototype provide a good feasible study on a specific application. Future research direction include the extension to various unseen location, as well as other potential application scenario.